
導語:你的手機為什么能一眼認出你?自動駕駛汽車何如"看"路?AI 又是何如從一張 X 光片里發現病情的?
謎底皆藏在計較機視覺(Computer Vision)里。它不是給機器裝錄像頭,而是讓機器實在"貫通"它看到的東西。
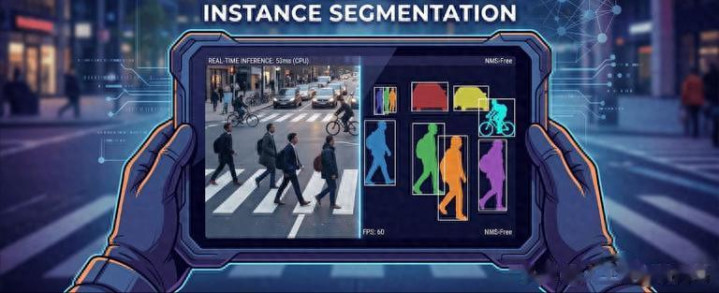
一、什么是計較機視覺?讓機器從"看見"到"看懂"
簡單來說,計較機視覺便是給 AI 裝上眼睛和大腦。
它屬于東說念主工智能的一個分支,中樞任務是讓機器懲辦、分析并貫通圖像和視頻。但"看懂"一張圖,對東說念主類是本能,對機器卻是地獄級難度——因為機器看到的,僅僅一堆像素數字。
為了從像素中提真金不怕火意旨,計較機視覺依賴三大中樞經過的勾搭:
經過
東說念主話翻譯
打個比喻
識別
圖中有什么?
你一眼認出這是貓照舊狗
重建
這些東西長什么樣?
你從相片里腦補出它的 3D 體式
重組
它們之間什么相關?
你看出"貓在沙發上"、"車在馬路左邊"
這三個經過絲絲入扣,機器才能實在"看懂"天下,而不是只當一臺"像素掃描儀"。

二、計較機視覺是何如"學會看病"的?
思知說念計較機視覺何如責任?最佳的例子便是醫學影像會診。
發射科大夫看胸部 X 光片找病情,既費眼又容易漏診。而計較機視覺系統,正在形成大夫的"第二雙眼"。它的學習經過,不錯分紅四步:
① 數據薈萃:先喂飽它
病院把千千萬萬張胸部 X 光片喂給 AI,每張皆要標注好——這張是"日常",那張是"肺炎"。莫得標注的數據,對 AI 來說僅僅一堆意外旨的像素。
除了病院自建數據集,業界還有 COCO、ImageNet、Open Images 等"內行講義",內部有幾千萬張帶標簽的圖片。
② 預懲辦:給圖片"好意思顏"和"擴列"
raw 數據頻頻不可徑直喂模子。AI 需要數據清洗和增強:
轉折亮度、對比度,讓病灶更明晰;
旋轉、翻轉圖片,東說念主為膨大數據集,讓 AI 見過"各式姿勢"的肺炎。
這就好比學生刷題,不可只作念原題,要作念變形題才能實在學會。

③ 模子選拔:CNN 是宿將,Transformer 是新貴
選什么"大腦"來學?傳統上,卷積神經薈萃(CNN)是圖像任務的全皆主力;懲辦視頻時,輪回神經薈萃(RNN)則更擅長捕捉幀與幀的時序相關。
但近幾年,視覺 Transformer(ViT)異軍突起。它把一張圖切成好多小塊(像言語模子里的"詞元"),再用自小心力機制分析塊與塊的相關。在好多圖像分類任務上,ViT 也曾能并排以致特出 CNN。
④ 模子考試:卷積、池化、反向傳播,三步走
這是最要津也最硬核的部分。咱們把它翻譯成"東說念主話":
第一步:卷積——提真金不怕火特征 AI 用一個叫濾波器(卷積核)的小窗口,在圖片上"掃雷"通常滑疇前,計較每個區域的特征。有的濾波器挑升找"角落",有的挑升找"紋理",有的挑升找"亮斑"。
對肺炎 X 光來說,AI 要收攏這些要津視覺特征:
肺部輪廓是否對稱;
有莫得特地的亮區(炎癥或積液);
紋理是否粗放、斑駁。
第二步:池化——執大放小 特征圖頻頻太大,池化層就像"壓縮包",保留最杰出的信息(比如取最大值或平均值),扔掉冗余細節。這么模子才能"商量小心力"。
第三步:全貫穿 + 反向傳播——糾錯升級 臨了,全貫穿層像"閱卷本分",概述所有這個詞特征給出判斷:這張 X 光是"日常"照舊"肺炎",概率各是若干?
如若猜錯了,模子開動反向傳播:從惡果倒推,計較每個參數的"職守",再用梯度下落轉折權重。一遍又一遍,直到荒唐率越來越低。
這個經過,內容上便是"作念題→對謎底→改錯→再作念題"的輪回。
三、計較機視覺的"手段樹":它到底穎異什么?
學成了的計較機視覺,手段點相當豐富。咱們挑幾個最實用的說:
1. 圖像分類:給圖片貼標簽
最基礎的能力。比如輸入一張 X 光,輸出"肺炎"或"日常"。ImageNet 挑戰賽便是比這個。
2. 對象檢測:不單認出你,還要框住你
比分類更進一步——先定位,再分類。馬路上不僅有"車",還要框出每輛車的位置。
經典算法有兩個門戶:
R-CNN 系列:兩階段檢測,先找"可疑區域",世界杯官方認證平臺再詳盡分類,精度高但慢;
YOLO:"只看一次",定位和分類一氣呵成,快到能及時懲辦視頻流。

3. 圖像分割:像素級的"精確摳圖"
對象檢測畫的是 bounding box(界限框),分割則是像素級的。它把圖像每個像素皆打上標簽,精確到物體的輪廓。
語義分割:只分類,不區別個體(所有這個詞車皆是"車");
實例分割:不僅分類,還區別"這是車 A,那是車 B";
全景分割:兩者結合,配景語義分割 + 遠景實例分割。

4. 面部識別:你的"生物密碼"
捕捉面部幾何特征——眼距、額頭到下巴的距離、鼻子輪廓、嘴唇體式。不管是手機解鎖,照舊機場安檢,皆是它在背后干活。

5. 姿態臆想:看懂你的當作
識別軀殼各部位的空間位置。VR 游戲里追蹤你的手勢,NASA 用它緩助空間站機械臂執取野心,皆是姿態臆想的落地場景。

6. OCR:讓紙質天下數字化
光學字符識別,從掃描件、相片里提真金不怕火筆墨。傳統 OCR 是一個字一個字認,咫尺基于 CNN 和 Transformer 的模子能整詞整句地智能識別,速率和準確率皆大幅進步。
7. 圖像生成:AI 也會"畫畫"
GAN(生成掙扎薈萃):生成器和判別器"傍邊互搏",直到生成器畫的圖真假難辨;
擴散模子:先給圖片加噪聲加到狀貌一新,再學會"去噪"規復,從而生周全新圖像;
VAE(變分自編碼器):把圖片壓縮成"靈魂代碼",再解碼成各式變體。
四、計較機視覺正在更正哪些行業?
技巧再酷,落地才有價值。計較機視覺的"飯碗",也曾伸到了九行八業:
表格
行業
誆騙場景
何如"看"的
醫療
肺炎會診、腫瘤分割
X 光/CT/MRI 圖像分類 + 實例分割
自動駕駛
避障、識別紅綠燈
對象檢測 + 場景貫通 + 圖像分割
零賣
無東說念主收銀、誣捏試衣
對象追蹤 + 面部/姿態臆想 + AR
制造業
質檢、庫存盤貨
視覺查驗 + 對象檢測
農業
病蟲害識別、精確除草
無東說念主機航拍 + 圖像分類
天外
著陸避障、小行星追蹤
對象檢測 + 對象追蹤
皇冠體育(CrownSports)官網舉個最迫臨生計的例子:亞馬遜的 Just Walk Out。你拿完商品徑直走,錄像頭和計較機視覺系統也曾"看"清你拿了什么,自動扣款,連列隊皆省了。
五、修復者器用箱:5 個主流器用
思脫手玩計較機視覺?這 5 個器用是業界標配:
OpenCV:老牌開源庫,2500+ 算法,C++/Python/Java 通吃,圖像懲辦初學首選;
TensorFlow:Google 出品,提供 CV 專用數據集和預懲辦器用;
Keras:高層 API,教程豐富,合乎快速上手圖像分類、分割、OCR;
Torchvision:PyTorch 生態的"視覺套件",內置常用數據集和預考試模子;
Scikit-image:Python 圖像懲辦庫,簡單易用,合乎初學者作念預懲辦。
六、60 年進化史:從貓的視覺踐諾到 AlexNet 封神
計較機視覺不是整夜爆發的,它走了整整 60 年:
1950s-1960s:神經生理學家給貓看圖像,發現大腦最早對線條和角落產生響應。同期,首臺圖像掃描儀出生,計較機第一次能"數字化看圖"。
1982:David Marr 忽視視覺層級表面;Kunihiko Fukushima 發明"通曉機",初次在神經薈萃中引入卷積層——這便是 CNN 的先人。
2000s:研討重點轉向圖像分類和對象識別。
2009:ImageNet 數據集發布,1500 萬張標注圖片,給計較機視覺提供了"超等講義"。
2012:多倫多大學團隊推出 AlexNet,在 ImageNet 競賽上把圖像識別荒唐率腰斬,徑直引爆了深度學習翻新,也奠定了今天計較機視覺的基石。
從"看懂線條"到"會診疾病"、從"踐諾室玩物"到"火星導航",計較機視覺用了 60 年,實在讓機器長出了"眼睛"。
寫在臨了
計較機視覺的終極野心,從來不是替代東說念主類的眼晴,而是幫咱們看到肉眼看不到的東西——X 光片里早期病情的微細暗影、出產線上 0.1 毫米的裂痕、天外中 millions 公里外的小行星軌跡。
下一次,當你用手機掃臉解鎖、看到自動駕駛汽車沉穩穿過路口、簡略傳說 AI 又緩助會診了一例荒廢病時,你會知說念:那不是魔法2026美加墨世界杯(中國),是計較機視覺在替咱們"看見"未來。